Announced today, the high-performance switch IC enables scale-up and scale-out for AI networks and supports co-packaged optics.
Today, Broadcom has announced that it’s shipping the Tomahawk 6 series switches, which they call the ''World’s First 102.4 Tbps Switch”. All About Circuits had the chance to interview Pete Del Vecchio, Data Center Switch Product Line Manager at Broadcom, to learn more about the product firsthand.
Tomahawk 6—102.5 Tbps Switch IC
As AI workloads continue to push datacenter boundaries, Broadcom reports that every large-scale AI network deployment planned for 2025 will rely on Ethernet-based fabrics, rather than InfiniBand.
“If you look at what's happened over the last, say, year and a half to two years, there has been a dramatic transition from InfiniBand to Ethernet,” says Del Vecchio. “The largest AI clusters are now being deployed with Ethernet, and it could provide equal to or higher performance than InfiniBand.”
In that context, Broadcom’s Tomahawk 6 is a 102.4 Tbps switch chip designed to consolidate Ethernet as the unified fabric for hyperscale AI clusters.

Tomahawk 6-100G (left). Tomahawk 6-200G (right)
The Tomahawk 6 builds on its predecessor’s foundation (in other words, the Tomahawk 5’s 51.2 Tbps) and incorporates new capabilities tailored for AI-driven communication patterns. Central to this evolution is support for both 100G and 200G PAM4 SerDes, including options for 1,024 100G lanes or 512 200G lanes, with electrically pluggable and co-packaged optics available. Such flexibility enables system architects to tune interconnect configurations for both legacy infrastructure and cutting-edge optical topologies without changing core silicon.
Support for Scale-Up and Scale-Out AI Workloads
Broadcom explicitly designed the Tomahawk 6 to address the diverging demands of scale-up and scale-out networks in AI infrastructure. Scale-up interconnects link XPUs within a tightly coupled compute node to facilitate high-throughput memory access and low-latency model parallelism. To this end, Tomahawk 6 enables single-hop connectivity for up to 512 XPUs in a scale-up domain, more than seven times the scale achievable with existing solutions.
By integrating Broadcom’s Scale-Up Ethernet (SUE) framework, the chip supports memory-semantic communication across XPUs over standard Ethernet, reducing dependency on proprietary interconnects like NVLink. On the design rationale behind Tomahawk 6’s scale-up support, Del Vecchio explains, “With Tomahawk 6, you can scale up to 512 GPUs or XPUs... you want to have a single hop, just a single switch hop for latency reasons and also for just communication and congestion management.”
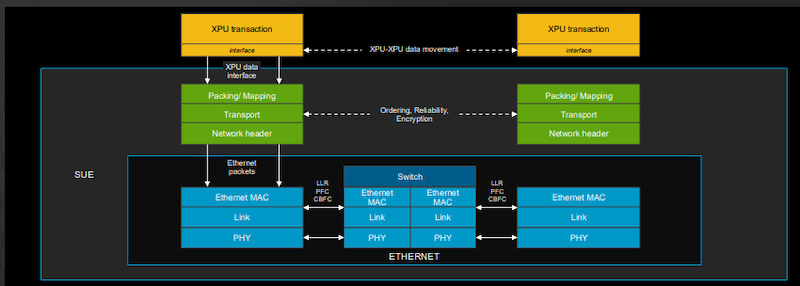
Tomahawk 6 supports open Scale-Up Ethernet.
In scale-out deployments, the switch provides the bandwidth and port density required to build flattened two-tier topologies supporting 100,000 or more XPUs per cluster. Competing switches with lower port speeds require three-tier topologies for equivalent reach, resulting in 67% more optics, increased latency due to extra hops, and roughly twice the network power consumption. Tomahawk 6’s 102.4 Tbps bandwidth permits large Clos fabrics with fewer components, translating to reduced infrastructure overhead and lower total cost of ownership.
Cognitive Routing and Load Balancing at Full Utilization
Traditional data center switches often operate below 70% utilization to mitigate congestion and minimize tail latency. AI networks, however, must drive fabric utilization beyond 90% to meet the demands of large-scale model training and inference. To sustain performance at such intensities, Tomahawk 6 incorporates Cognitive Routing 2.0, Broadcom’s next-generation adaptive routing and telemetry suite.
The switch uses network-wide intelligence to dynamically rebalance traffic based on real-time congestion metrics. Compared to static equal-cost multipath (ECMP) routing or hash-based schemes, Tomahawk 6 performs egress link selection with global visibility into path congestion. In practice, this results in up to 50% higher throughput under load and response times to link failures that are 10,000 times faster than standard Ethernet failover mechanisms. The system steers active flows away from degraded paths and can trim and retransmit congested packets to maintain performance without stalling.
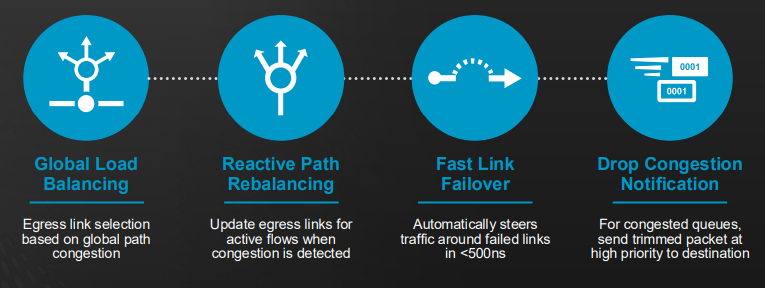
Broadcom Cognitive Routing 2.0
Cognitive Routing 2.0 also includes enhanced support for arbitrary topologies, including Clos, torus, rail-optimized, and scale-up domains. It incorporates real-time physical link monitoring that unlocks predictive maintenance by identifying degrading optical or copper channels before failure occurs.
Power-Efficient Optics and Flexible Interconnect
Power density constraints remain a gating factor for hyperscale AI cluster expansion. In today’s AI data centers, optics contribute up to 70% of network power consumption. Tomahawk 6 mitigates this by enabling two-tier fabrics where three-tier designs were previously required. The availability of both pluggable optics and co-packaged optics (CPO) variants gives operators further control over thermal envelopes. On this, Del Vecchio explains:
“If you need to use any other technology, you couldn't connect those GPUs in two tiers. You'd have to go to three tiers of networking. You would wind up using 67% more optics and almost 2x the power for the network.”
Broadcom’s CPO option leverages its experience from previous Tomahawk generations and offers reduced power and lower link flaps. The chip also supports extended reach direct-attach copper (DAC) and passive backplane connections, capitalizing on Broadcom’s SerDes design, which exceeds 45 dB channel reach at 200G PAM4. These capabilities enable hyperscalers to deploy high-density, low-power switch interconnects without compromising port reach or requiring high-power, DSP-based optics.
A Unified, Open Platform for AI Infrastructure
Ultimately, Broadcom is positioning the Tomahawk 6 as part of a vertically integrated Ethernet platform that spans switches, NICs, optics, and software. The switch itself interoperates with Broadcom’s Thor NICs and NIC chiplets, which can be integrated into XPUs for flexible endpoint scheduling. It also complies with the Ultra Ethernet Consortium specifications for compatibility with open-source congestion management, telemetry standards, and AI model transport protocols.
This open-standards orientation helps hyperscalers who want to optimize XPU fungibility. Whether an interface is used for scale-up or scale-out networking, operators can dynamically reconfigure it according to workload demands. All things considered, the flexibility reduces hardware sprawl and enables cloud providers to optimize GPU allocation without being locked into specific interconnect roles or topologies.
Industry Outlook
In an environment where AI model complexity and hardware acceleration demands scale exponentially, Broadcom’s approach with Tomahawk 6 reflects a broader trend where networks are central to system performance and efficiency. As Del Vecchio tells it, “What we're doing here is actually making the network and all the training much more efficient... so you can just get the network out of the way, get the traffic passing between the GPUs as quickly as possible.”
Broadcom believes that the race to optimize interconnects at both the chip and fabric levels will define the next phase of AI system design, and hopes Tomahawk 6 will position them in the front of the pack.
All images used courtesy of Broadcom.

