Announced today, the new device challenges the assumption that Ethernet can't support small packet sizes or optimized transport paths.
Broadcom today announced that its Tomahawk Ultra switch IC has entered production. Designed from the ground up for high-performance computing (HPC) and tightly coupled AI scale-up networks, Tomahawk Ultra is meant to dispel long-standing criticisms of Ethernet in latency-sensitive environments.

Broadcom engineered the Tomahawk Ultra to transform the Ethernet switch for high-performance computing and AI workloads.
Broadcom’s rearchitecture challenges the assumption that Ethernet is inherently high-latency and lossy, unable to support small packet sizes or optimized transport paths. All About Circuits heard from Pete Del Vecchio, Broadcom's data center switch product line manager, to learn more about how the switch is changing the narrative on Ethernet.
Addressing Ethernet’s Shortcomings
Del Vecchio explained that Ethernet’s perceived shortcomings in HPC and AI scale-up systems historically stemmed from the design priorities of traditional data center switches. These switches prioritized high throughput for large packet sizes and global-scale deployments.
“What we decided to do was to first off shatter every misconception, every design point that was not addressed by Ethernet before,” Del Vecchio said.
Tomahawk Ultra focuses on ultra-low latency, small-packet throughput, and lossless operation. It achieves 250-ns switch latency at full 51.2-Tbps throughput and handles 77 billion packets per second—a figure driven by its ability to process minimum-size 64-byte frames at line rate. According to Broadcom, even its higher-bandwidth Tomahawk 6, announced last month at 102.4 Tbps, delivers only half the packets-per-second performance.
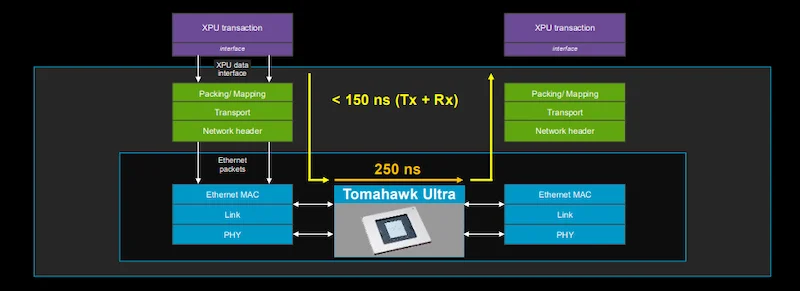
Scale-Up Ethernet with Tomahawk Ultra.
In concert with the open-standard Scale-Up Ethernet (SUE) specification, Tomahawk Ultra delivers end-to-end XPU-to-XPU latency under 400 ns, including transit through the switch. Notably, the switch achieves this without resorting to proprietary protocols or closed ecosystems. Instead, it retains Ethernet compliance while introducing architectural changes that reshape link behavior, congestion control, and packet handling at the silicon level.
Optimized Headers and Reduced Overhead
One of the architectural advances in Tomahawk Ultra is its support for optimized Ethernet headers. Standard Ethernet implementations often require IPv4 or UDP headers as large as 44–46 bytes, which significantly impairs efficiency for minimum-size packets. For AI and HPC workloads that rely on small, high-frequency messages, such an overhead consumes valuable bandwidth and inflates processing time.
Tomahawk Ultra introduces an adaptable, compressed Ethernet header format that reduces packet overhead to as little as 6 bytes. These headers maintain full Ethernet compliance and interoperate with standard MAC and PHY implementations. However, they eliminate the need for multi-layer encapsulation in tightly coupled systems where packets typically traverse a single switch hop.
“We’re showing you how you can have an optimized header that’s still Ethernet compliant with much less overhead on the wire,” Del Vecchio said.
This reduction in header size directly boosts effective payload throughput for minimum-size packets and simplifies XPU design. It also enables finer control over traffic shaping and flow classification for workloads that are distributed across many cores.
Lossless Fabric With Hardware-Based Flow Control
Tomahawk Ultra also integrates a dual mechanism to achieve a lossless Ethernet fabric. At the link level, Broadcom employs Link Layer Retry (LLR) that combines IEEE-standard Forward Error Correction (FEC) with retransmission protocols to detect and correct frame-level errors without requiring application-layer intervention. Broadcom claims that this feature minimizes retransmission overhead and latency so that switches and XPUs can handle errors locally and immediately.
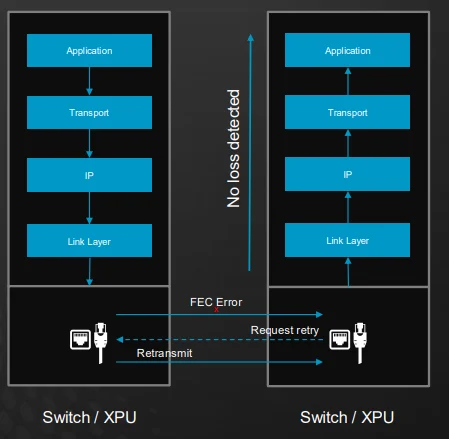
A working example of the lossless LLR.
To prevent buffer overflows, the switch adds Credit-Based Flow Control (CBFC), a mechanism in which receivers communicate available buffer credits to transmitters. Transmission occurs only when the receivers indicate sufficient space. That way, it eliminates the congestion-driven packet drops typical in lossy networks.
These mechanisms are implemented entirely in hardware and operate on a per-hop basis, reducing the reliance on end-to-end acknowledgments and dramatically lowering latency. Broadcom also notes that these features, once relegated to proprietary interconnects like InfiniBand or Omni-Path, are now standardized under the Ultra Ethernet Consortium (UEC) and incorporated directly into Tomahawk Ultra’s architecture.
In-Network Collectives to Offload XPUs
Tomahawk Ultra introduces support for In-Network Collectives (INC), a feature that offloads multi-node communication patterns from XPUs to the switch itself. INC targets operations like AllReduce, AllGather, and Broadcast that rely on the aggregation of partial results computed across many accelerators.
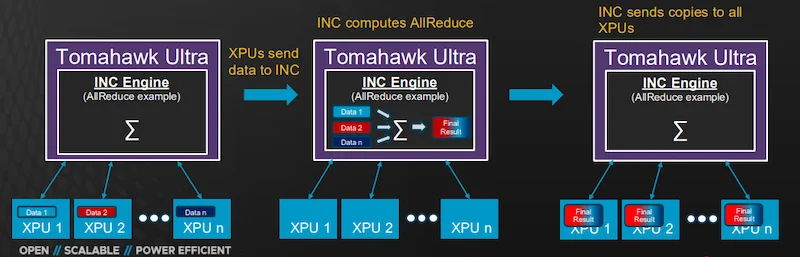
INC reduces job completion time.
Instead of forcing XPUs to handle the collective computation by exchanging multiple rounds of data, the switch aggregates and distributes the results internally. For example, in an AllReduce operation, each XPU sends its computed tensor to the switch, which performs the summation and redistributes the final result back to all devices. This reduces job completion time by both lowering computation latency and cutting the total data traffic across the network fabric.
Broadcom implemented INC support directly in the silicon pipeline to sidestep any performance penalty, accelerate the convergence of large language models, and support tight synchronization in parallel workloads.
A Pivot to Ethernet
According to Broadcom, Tomahawk Ultra is a turning point in the debate over Ethernet’s viability in scale-up networks. Broadcom’s executives anticipate that Ethernet, while already dominant in data center and scale-out AI, will extend its reach into the scale-up domain to displace closed interconnects like NVLink and UALink.
“Even Nvidia—their messaging has shifted pretty dramatically—to be more about Ethernet,” Del Vecchio said. “Are things like Omnipath and InfiniBand on the way out? I think so.”
All images used courtesy of Broadcom.

